
41·
58 minutes agoWouldn’t Turkey or someone sour this?
But if it’s actually possible, that’s fascinating… if Ukraine can’t push back quickly, wouldn’t it “force” an end to the war? Russia would have a red line it absolutely can’t cross, no hope of advancement, and likely just claim everything on the other side. Surely they wouldn’t continue a grinding stalemate where Ukraine has a “safe zone” to operate out of.
If Ukraine does retain its ability to push back hard by the time this happens, and doesn’t go for a truce, then that’s especially peculiar. Walling off a part of their territory as actually untouchable seems like a massive strategic advantage for Ukraine.


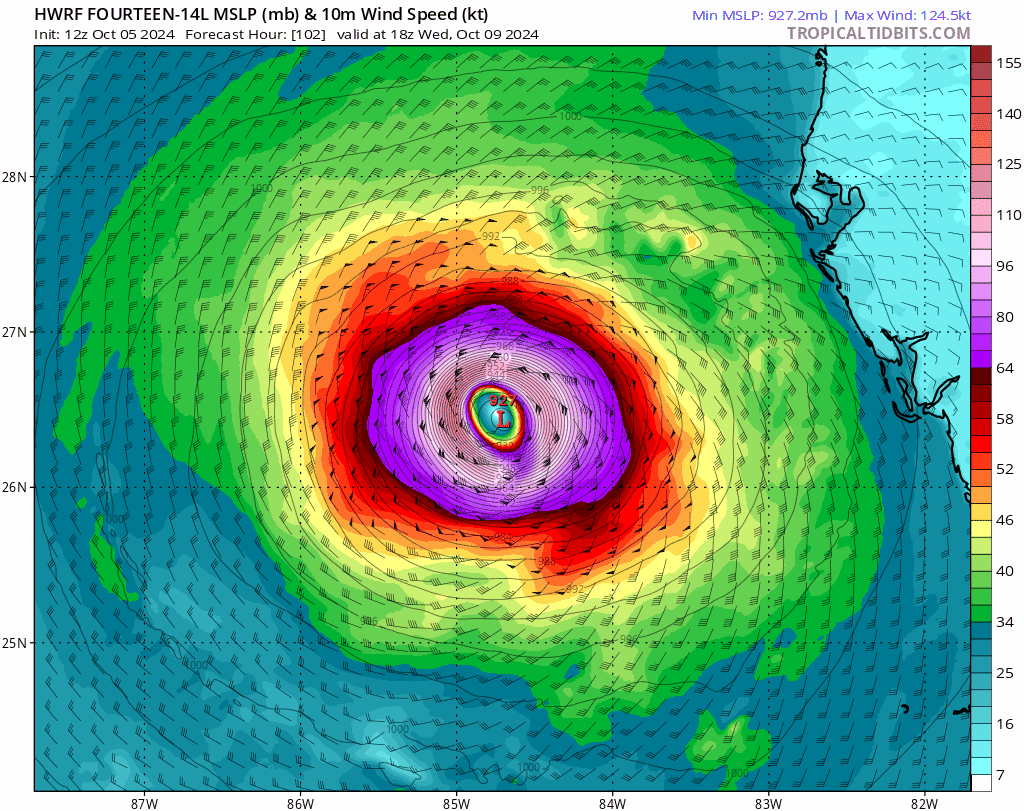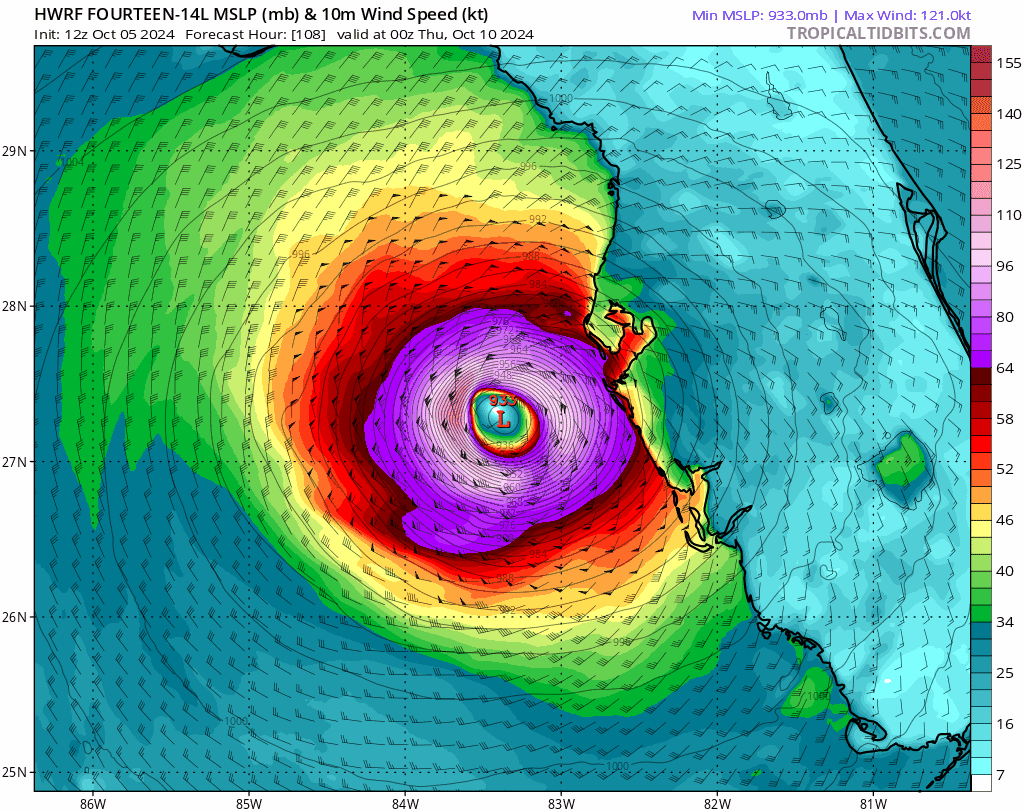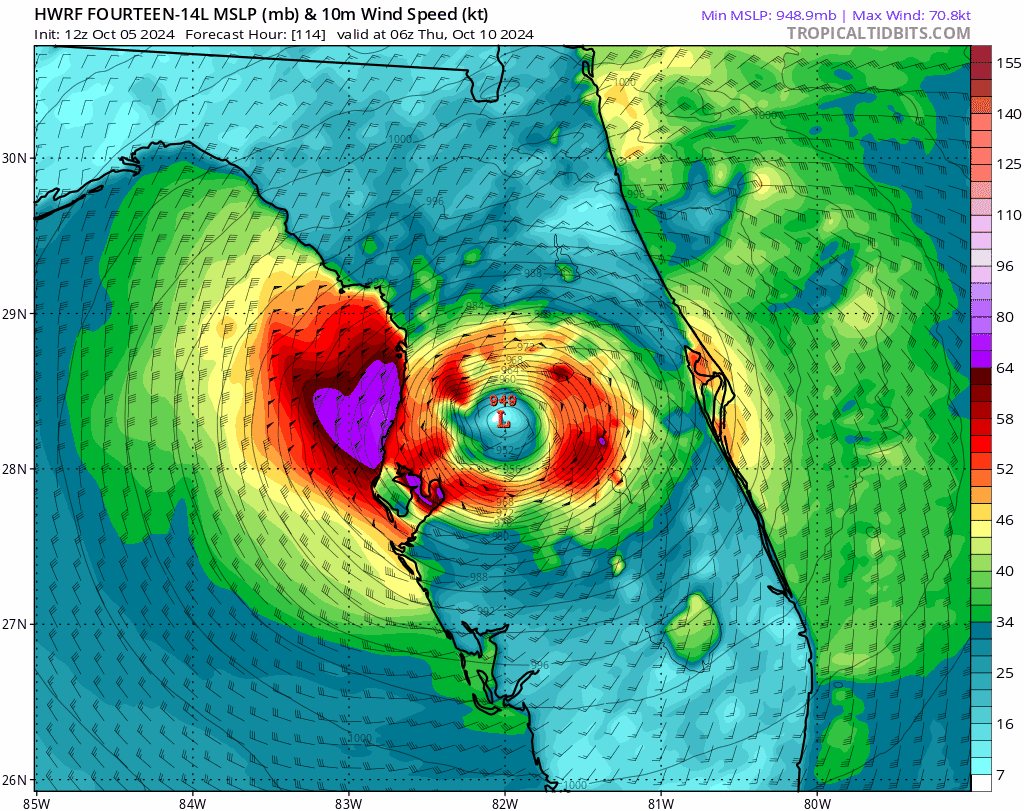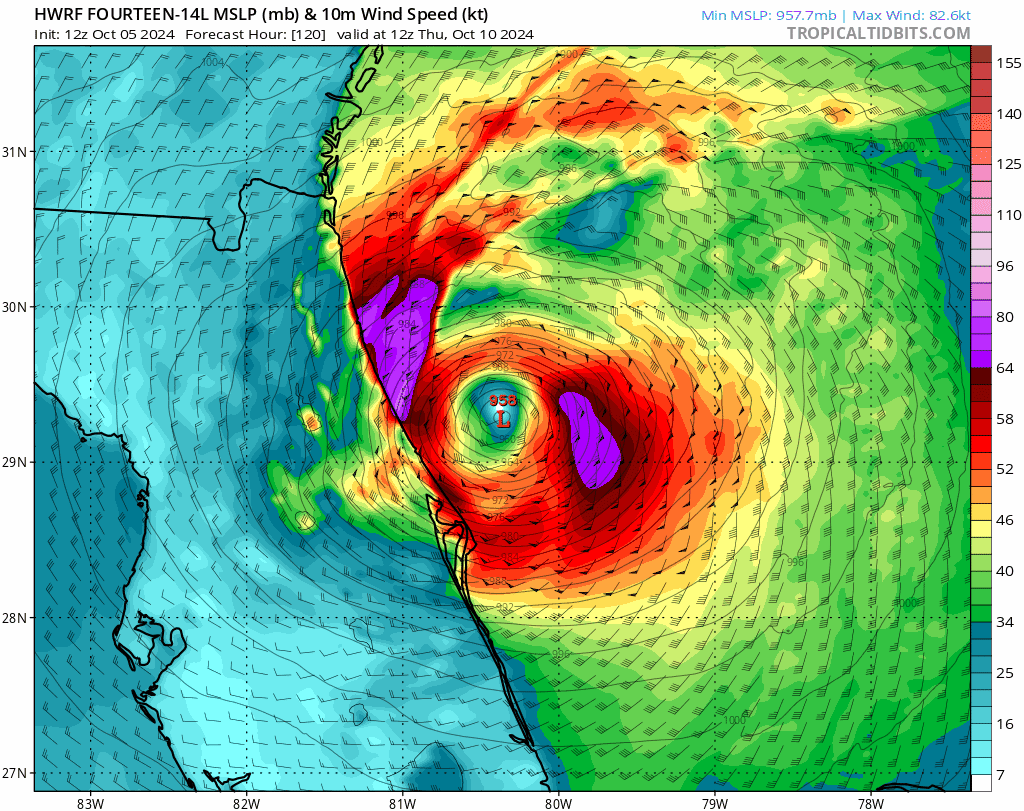










Doesn’t Russia have defensive pacts of their own, with North Korea and CSTO: https://en.wikipedia.org/wiki/Collective_Security_Treaty_Organization#History
They would undoubtedly claim to be attacked if Ukraine uses weapons in “their” territory the next time around, and at the very least drag Belarus (and NK as an explicit supplier) in with them.